
What is a TaskBot?
Regular conversational agents, or “SocialBots”, simply aim to engage users in general conversations around politics, travel, or movies. A “TaskBot” is an AI system that works with a user to accomplish a specific goal1. For example, walking a user through identifying what’s wrong with their bike and then supporting them in fixing it. We focused on domains that require precise explanations such as cooking, crafts, and Do it yourself (DIY).
")

Network of Small Language Models (SLMs)
Our solution was to develop a system based on multiple Small Language Models (SLMs). These open-source AI models are between 100 million and 10 billion parameters (10-100x smaller than GPT3), allowing secure on-prem deployment on a single GPU.
Due to latency requirements, we predominately used T55 and BERT6 large models, which are under 1 billion parameters. Each SLM could focus on a specific tasks:
- Offline pipelines: We used SLMs to automatically extract millions of tasks from trusted sources, i.e., Gordon Ramsey’s cooking recipes.
- Functionalities: We created specialised SLMs for different sub-components, i.e., searching for tasks, answering questions, or using other tools such as setting timers.
- Neural Decision Parser: This was the brain of the system that managed the conversational state. Specifically, this SLM selected which subsystem to call given a user utterance.
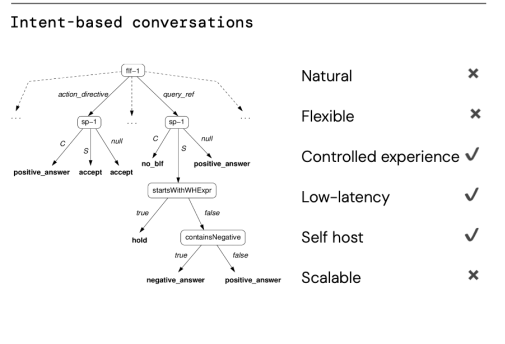
Overall, this system met all our criteria, retaining the positive aspects of LLMs (natural, flexible, scalable) but with a more controlled experience, low latency, and affordable self-hosting.
")
Example: using an SLM to manage conversational state
After having a flexible system of SLMs we wondered – how do we actually manage these diverse daily conversations? We developed the Neural Decision Parser, a T5 Large SLM (700m parameters) that takes in conversation context and task state and generates Python code to call system sub-components. For example, if the user says “shepherd’s pie please”, the Neural Decision Parser will generate parameterised code, Search (”shepherd’s pie”), to call the task search system. This SLM “brain” allows for flexible handling of complex conversations.
")
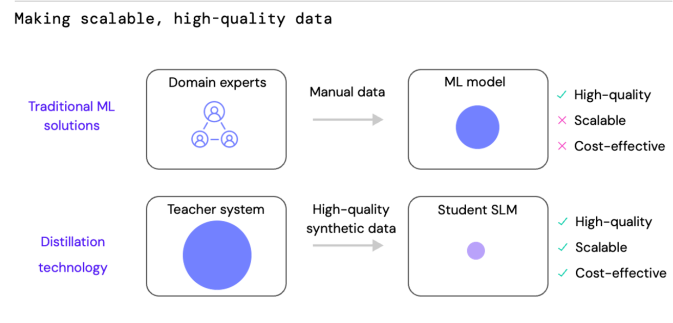
Our solution was to use knowledge distillation7 to create scalable, high-quality synthetic data to train our SLMs. Distillation is where we use the output on a larger, more computationally intensive AI model (the “teacher”) to train a smaller AI model (the “student”) that is suitable for production with lower latency or 24/7 resource cost. Thus, unlike the manual annotation process, distillation creates high-quality training data for machine learning models in a scalable and low-cost manner.
Example: Distilling the Neural Decision Parser
As discussed earlier, the Neural Decision Parser is a key component that manages conversational flows. This model takes into account the context of the conversation, task state and needs to output the correct function call. This is a complex semantic parsing problem with a large input (conversational context) and output (parameterised sub-system calls) space. Furthermore, we need the model’s inference latency to be under 1 second and capable of being self-hosted on a small GPU. However, due to the size of the input/output space, it would not be practical to manually annotate a dataset capable of training an SLM for this task.
Therefore, we used distillation to create a large, high-quality synthetic dataset. We started with the 100,000s of raw task data and some initial seed annotations. We used a large model3 ( 175 million parameters) to synthesise conversations for different task states (our synthetic inputs). We then used another pass of prompting an LLM to create the synthetic outputs. We used domain experts in the loop to improve the chaining of the LLMs and refine the LLM prompts to ensure the generated data was of sufficient quality.
")
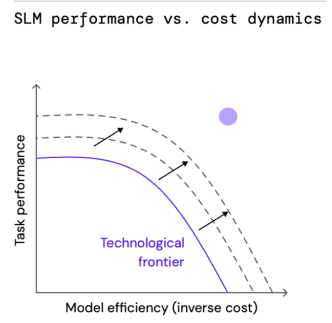
We used this large dataset to fine-tune a T5 Large SLM (0.7bn parameters) that achieved performance on par with GPT3. However, this SLM was 100x smaller, had an inference latency of 0.5 seconds versus 4-5 minutes for our data generation pipeline, and could be deployed on a small GPU for £700/month.
Continuously improving system
Another benefit of having a cost-effective and scalable way of creating training data was that we could regularly re-run the distillation pipelines. Specifically, the system could be updated based on new task data and user sessions. This led to a system that continuously improved to become better and more robust for users.
")
Results
The winning formula for the Amazon Alexa Challenge was a network of specialised SLMs and a scalable way to create high-quality training data. This is reflected by a strong user rating that saw a consistent uptrend as the system learned and improved. Our approach was especially true for complex, long conversations (over 3 minutes) that require a flexible system to succeed.
")
- Ipek, Anna Gottardi Osman, et al. “Alexa, Let’s Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance.” arXiv preprint arXiv:2209.06321 (2022). ↩︎
- Xie, Tian, et al. “Converse: A tree-based modular task-oriented dialogue system.” arXiv preprint arXiv:2203.12187 (2022). ↩︎
- Brown, Tom B. “Language models are few-shot learners.” arXiv preprint arXiv:2005.14165 (2020). ↩︎
- Foosherian, Mina, et al. “Enhancing pipeline-based conversational agents with large language models.” arXiv preprint arXiv:2309.03748 (2023). ↩︎
- Raffel, Colin, et al. “Exploring the limits of transfer learning with a unified text-to-text transformer.” Journal of machine learning research 21.140 (2020): 1-67. ↩︎
- Devlin, Jacob et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” North American Chapter of the Association for Computational Linguistics (2019). ↩︎
- Gou, Jianping, et al. “Knowledge distillation: A survey.” International Journal of Computer Vision 129.6 (2021): 1789-1819. ↩︎