This blog post examines how Deepseek’s distillation process, alongside Malted AI’s task-specific approach, highlights the potential for developing efficient, small language models that focus on accuracy, specialised knowledge, and reduced computational overhead, offering a more tailored solution for enterprise AI applications.

There has been significant hype around Deepseek building a performant model for only $6M, through the distillation of OpenAI, compared to the massive costs of training OpenAI’s o1 model (1). This has led to substantial press around Deepseek’s R1 model release, including picking a winner in the US vs. Chinese AI race, predicting Nvidia’s future share price, moral and legal judgments on copyright infringement, and much more. This article deliberately does not address any of these broader topics or predictions and instead focuses solely on distillation – how Deepseek could have used distillation and how Malted AI is using distillation for task-specific models.
So what is distillation? Distillation describes the process of transferring the capabilities of a large model to a smaller model. Despite the many ways to achieve this, current implementations of distillation for large language models (LLMs) use datasets generated by the large model as a way to fine-tune the smaller model.
Naturally, the way the dataset is created by the large model is very important to the downstream performance of the smaller model. Through examining their research paper, Deepseek created this dataset in multiple stages including manual annotation, LLM sampling, and reinforcement learning (2). By unpacking how data is used to train the R1 model, we can shed light on where OpenAI’s data ‘could’ have been used and demonstrate which models and distillation techniques can be applied to train smaller reasoning models.
Even with the largest models, reasoning is still unstable putting into question the best approach for AI in enterprise. At Malted AI, we take a focused approach to AI, contrasting with general-purpose models like Deepseek’s. In the last section, we outline how reasoning and distillation can yield efficient and performant small language models (SLMs) that can work together to solve complex tasks. We believe this is the future of distillation and the path to deploy highly specialised AI into production.
All language models predict text one word (or token) at a time to answer user questions. Typically, whether giving legal advice or summarising text, language models begin returning an answer to users as soon as they generate the first token.
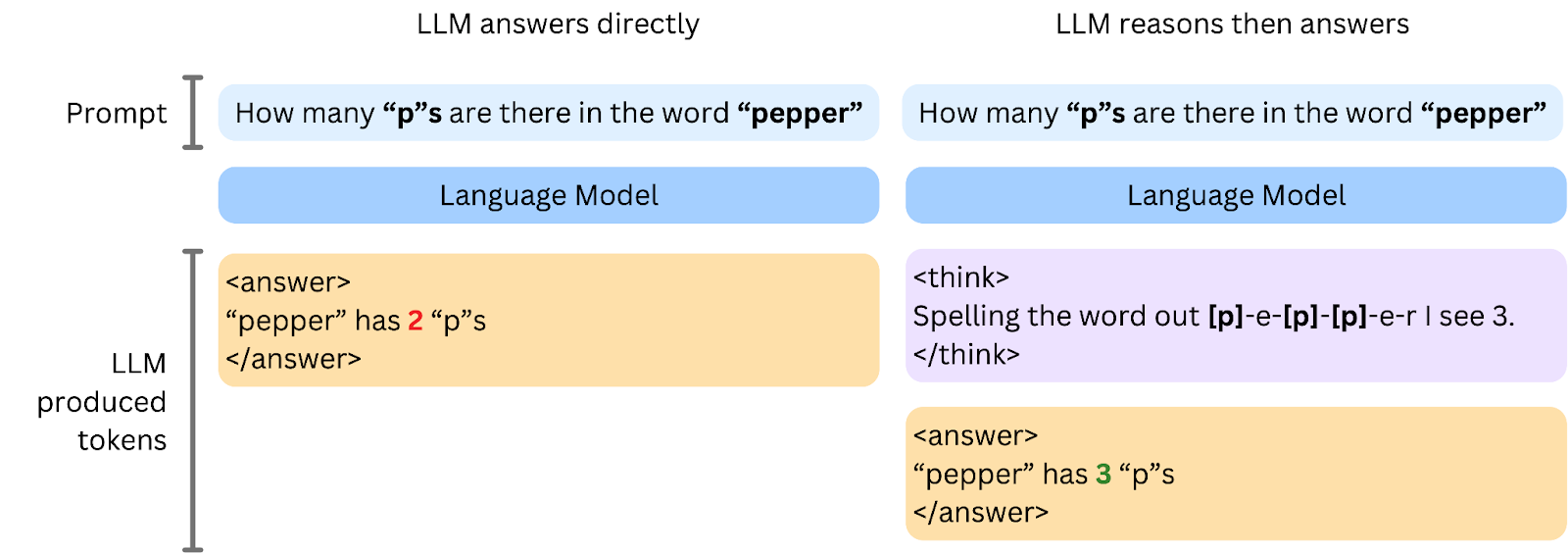
Reasoning models encourage the model to start the answer by explicitly predicting a reasoning trace before continuing with the answer. Deepseek-R1 shows this reasoning process leads to better performance in challenging tasks. However, this process is computationally expensive.
By examining the Deepseek paper, to develop AI models (Deepseek-R1 and “distilled” models) that can reason in this format, the training process followed these key steps:
- Cold Start Dataset: Training began with a carefully curated dataset of thousands of examples, refined by human annotators and LLMs to kickstart the reasoning output format.
- Verifiable-reasoning RL: The cold start fine-tuned model was used to rollout reasoning traces to verifiable answers. This required a set of prompts and answers to seed generation. Reinforcement learning (RL) allows the model to explore the reasoning space as long as the final answer is correct.
- Rejection sampling: The RL reasoning model was then used to predict answers on a more general dataset. The model-produced reasoning responses were judged by an external LLM (Deepseek-v3 in this case) resulting in 600k samples.
- Supervised Fine-Tuning: The 600k non-rejected samples were combined with additional 200k non-reasoning samples to make a high quality dataset for supervised fine-tuning. This dataset is the basis for all published models including R1.
- Preference tuning: For each model, a secondary RL phase was performed to align with human preferences.
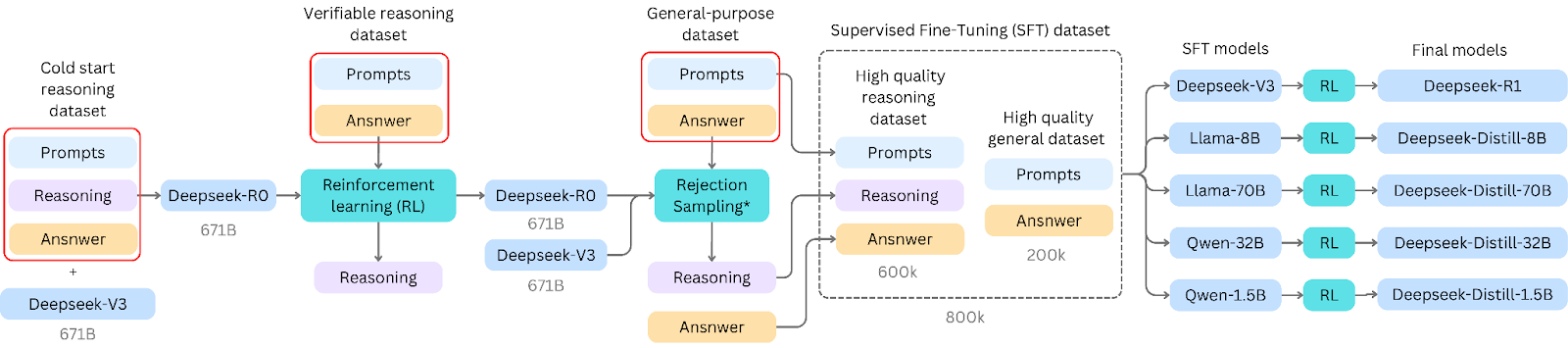
As we show in the training pipeline diagram above, highlighted in red there are several locations where prompts and ground-truth answers are required to yield a model. Prompts need to be diverse in scope and complexity to be effective in dataset generation since reasoning in both RL and rejection sampling stages is only expressed in response to a prompt, even if synthetically made. Similarly, the cold start data needs to be densely annotated and can be assisted through the use of LLMs for summarisation for formatting or first drafts. Cold start data and verifiable reasoning data can be in the order of thousands of samples while general-purpose data can be orders of magnitude larger. These are all places where data from external models (such as OpenAI) could be introduced whether for prompt inspiration or draft solutions and thus contributed to the creation of Deepseek-R1 and derivatives.
Another important finding from this diagram is that the reasoning in Deepseek distilled models does not derive from Deepseek-R1 but rather from a pipeline involving non-reasoning models and the more unstable Deepseek-R0 model. The supervised fine-tuning dataset is the bottleneck for all reasoning capabilities.
Although exciting, the Deepseek report and recent o1 findings suggest that reasoning in even the largest language models is unstable (3). Some reasoning traces are over 8,000 tokens long before producing an answer and suffer from infinite repetition, language swapping, and non-determinism. These issues are exacerbated when reasoning with small models that struggle to maintain a long thread of thought. This unreliability and token requirements leading to latency, don’t suit the needs of enterprises.
At Malted AI, we take a focused approach to AI through leveraging distillation. While general-purpose models like Deepseek’s LLMs demonstrate impressive capabilities across a wide range of tasks, we focus on task-specific small language models that prioritise accuracy, efficiency, and specialised expertise. We are big fans of reasoning, but we use it to build the highest quality final answers, leaving the small models to solely produce the answers. Here’s where we differ.
Focusing on Domain-Specific Tasks
Enterprise tasks are often highly specific and demand reliable, deterministic results. Unlike general models that handle broad, open-ended tasks, enterprise tasks frequently involve nuances and information unique to a company’s operations. For instance, classifying documents with company-specific tags requires a level of precision and domain knowledge that general-purpose models simply cannot offer or are not aligned to.
DeepSeek-R1 and its “distilled” siblings, despite their advanced reasoning capabilities, are designed as general-purpose models and lack domain-specific knowledge. While they can handle a range of tasks, achieving optimal performance in specialised enterprise scenarios requires instilling domain-specific knowledge into the model. This is where task-specific models come into play.
Through distillation, we take general-purpose models like DeepSeek-R1 and distil them into smaller, specialised versions tailored for specific tasks and company needs. These distilled models focus solely on one task at a time, whether it be classification, information extraction, or summarisation, enabling them to deliver results with a higher level of accuracy, efficiency, and specificity. We then build a network of these small language models, each contributing to a part of a more complex task.
Efficiency Through Fine-Tuning: No Need for Reasoning during Inference
During the distillation process, reasoning plays a crucial role, particularly when the distillation data is generated from the teacher models. This reasoning ensures that the model can be aligned to generate high-quality, task-specific outputs.
However, once an SLM has been distilled from synthetic data, reasoning becomes unnecessary during inference. To be more specific, our SLMs no longer need to reason as they rely on the patterns captured and distilled from the teacher, enabling them to directly output the answer with minimal computational overhead. This focus on efficiency allows our models to deliver fast, accurate results while keeping deployment size small and processing time short.
Hence, in contrast to general-purpose LLMs, which require extensive reasoning during both training and inference, our small, task-specific models eliminate the need for reasoning during inference, achieving SLM inference times in milliseconds (compared to up to 10 minutes for Deepseek-R1), while significantly lowering hosting costs, with GPU expenses under $1,000/month versus approximately $30,000/month for Deepseek-R1.
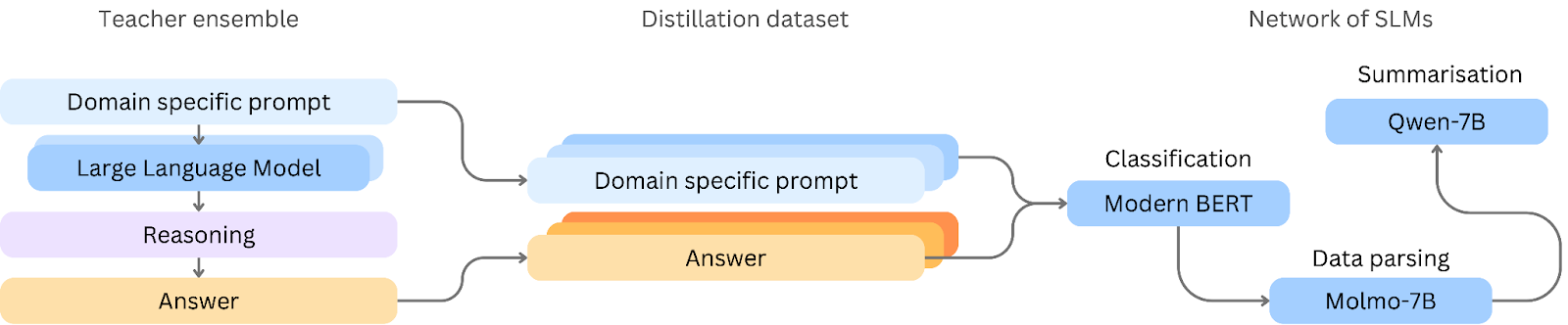
Model Agnostic: Tailored Architectures for Each Task
Lastly, we take a comprehensive view of the LLMs landscape, carefully selecting the most appropriate architecture for each task. For example, BERT models are still the standard for classification tasks despite their relatively minute size (i.e., 300M parameters vs. Deepseek-R1’s 671B parameters). Rather than relying on a one-size-fits-all approach, we choose from a range of advanced models and architectures that best suit the specific requirements of the application. Our advantage lies in distillation, refining and guiding models using synthetic data generation to achieve maximum efficiency and effectiveness, rather than simply adopting the latest general-purpose LLM or SLM for inference. This task-focused, adaptable strategy ensures we always employ the most powerful tools available, optimising performance and delivering high-quality, tailored results that precisely meet our clients’ needs.