Research
DeepSeek and the Future of Distillation
When DeepSeek claimed they'd built a model rivalling OpenAI's best for just $6 million, the internet lost its mind. Press coverage went in every direction: who's winning the AI race, what it means for Nvidia's stock, whether it counts as copyright infringement. We're not going to relitigate any of that here.
This article is about one specific thing: distillation, what it actually is, how DeepSeek likely used it to build R1, and how we're using it at Malted AI to build something quite different.

Key Takeaways
Distillation trains a small AI model using outputs from a large one, rather than from scratch
DeepSeek's R1 was built through a multi-stage pipeline that could have incorporated OpenAI's data at several points
Reasoning makes models more accurate but slow. DeepSeek-R1 can take up to 10 minutes to respond
Malted AI's task-specific models respond in milliseconds at under $1,000/month in GPU costs, versus ~$30,000/month for DeepSeek-R1
So what is distillation? Think of it like an apprenticeship. A senior expert (the large model) demonstrates how to handle thousands of different situations, and a junior hire (the small model) learns by studying those examples, not by starting from scratch. In AI terms, the large model generates a training dataset, and the small model learns from that instead of raw internet data. The small model never reaches the same breadth as its teacher, but for specific tasks it can match or even exceed it.
How that training data gets created matters enormously. DeepSeek's research paper shows they built theirs in stages: manual annotation, AI-generated examples, and reinforcement learning. Tracing that process lets us identify where OpenAI's data could have entered the picture, and what it means for how reasoning gets passed down to smaller models.
Reasoning, it turns out, is still messy even in the biggest models. That instability shapes everything about how you'd want to deploy AI in a real business, and it's why Malted AI's approach looks pretty different from DeepSeek's.
Building Deepseek-R1
Every language model works the same basic way: it predicts the next word (or "token") based on everything that came before. Ask it a question and it starts generating an answer immediately, one token at a time.
Reasoning models do something different. Before answering, they produce a chain of thought, working through the problem step by step, out loud, before committing to a final response. It's the AI equivalent of showing your working.
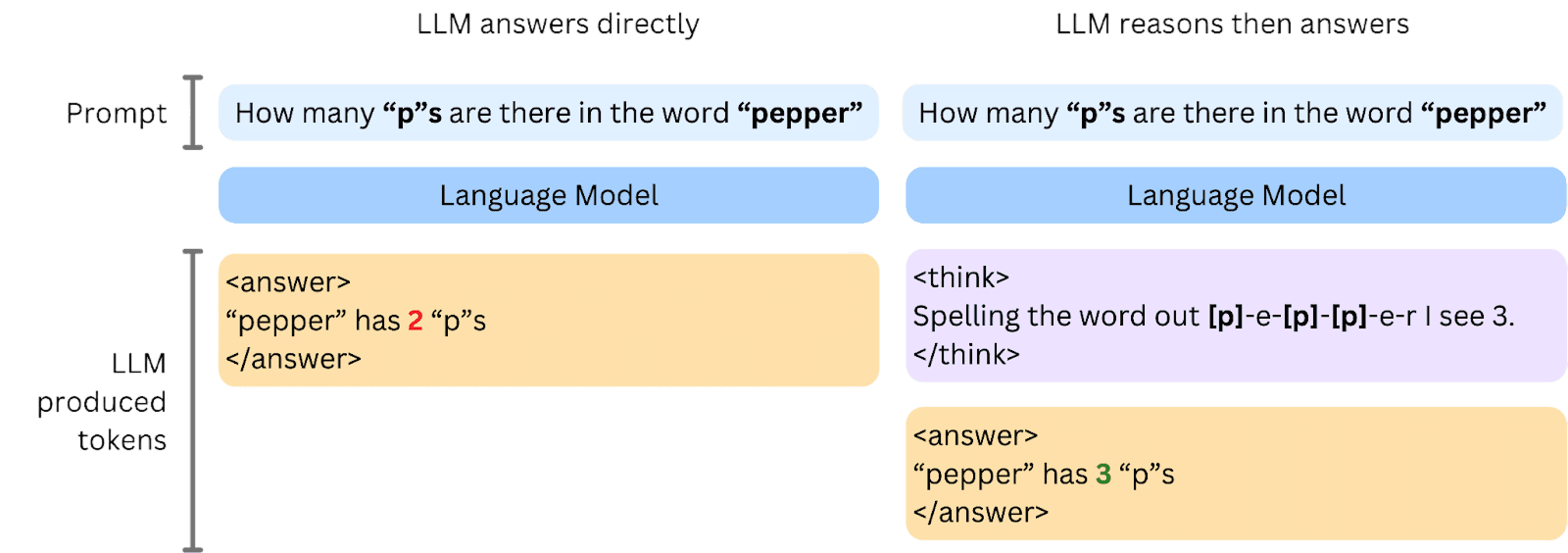
DeepSeek-R1 uses this approach, and their paper shows it genuinely improves accuracy on hard tasks. The downside? It's slow and expensive to run.
Building a model that reasons well required a careful multi-stage training pipeline:
Cold Start Dataset: Before any large-scale training, DeepSeek assembled thousands of hand-annotated examples in the right format to teach the model what a reasoning trace should look like. Think of it as giving the model a template for how to think.
Verifiable-reasoning RL: They then used reinforcement learning (RL) to let the model explore different reasoning paths freely. The rule was simple: the final answer has to be correct. How you get there is up to you. This is how the model learned to reason rather than just recall.
Rejection sampling: The reasoning model was run on a much larger general dataset, and an external model (DeepSeek-v3) acted as a judge, filtering out poor responses. The result was 600,000 high-quality reasoning examples.
Supervised Fine-Tuning: Those 600k examples were combined with 200k non-reasoning examples to create the core training dataset used for all published models, including R1.
Preference tuning: A final pass aligned each model's outputs with human preferences, making them sound and behave in ways people actually find useful.
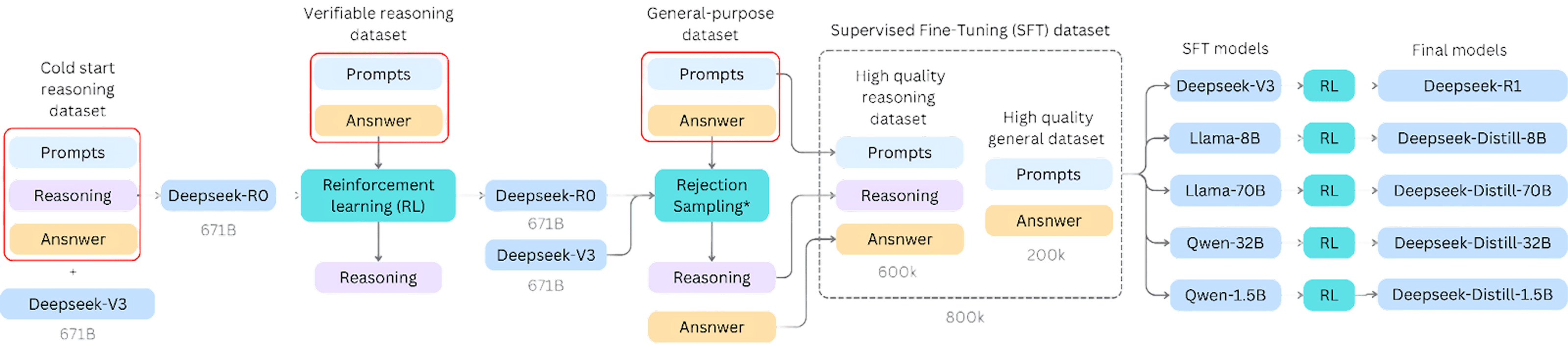
There are several points in this pipeline where external data could have fed in. Prompts need variety and scale to make both RL and rejection sampling work, and you can draw that variety from anywhere: manually written examples, synthetically generated ones, or outputs from other models. The cold start data especially benefits from LLM assistance in drafting and formatting. Those are the places where OpenAI's data could have played a role, whether for prompt ideas or draft answers.
One finding that doesn't get much attention: the reasoning in DeepSeek's smaller "distilled" models doesn't actually come from R1. It comes from an earlier, less stable model called R0. R1 is the polished final product; R0 is the raw reasoning engine underneath. The supervised fine-tuning dataset is the real bottleneck, and it determines how well any of the downstream models can reason.
Here's the thing though: even R1 isn't fully reliable. Some reasoning traces run over 8,000 tokens before the model produces an answer. They can loop, switch languages mid-thought, or produce different answers to the same question on different runs. These problems get worse in smaller models, which struggle to hold a long train of thought together. For a business that needs consistent, predictable outputs, that's a genuine problem.
R1 is the polished final product; R0 is the raw reasoning engine underneath.
Malted AI's Unique Approach: Distilled, Task-Specific Models
We're big fans of reasoning, but not for everything. At Malted AI, we use reasoning where it counts (building training data) and then leave it behind once our models are in production.
The result is a very different kind of product from DeepSeek's.
Focusing on Domain-Specific Tasks
General-purpose models like DeepSeek-R1 are impressive because they can handle almost anything. But "almost anything" isn't the same as "your specific thing." Enterprise work tends to be narrow and exact. Classifying a document against your company's internal taxonomy, extracting specific fields from a contract, flagging a particular type of customer complaint. These tasks have precise rules and context that a general model simply hasn't been trained on.
We start from a general model and distil it down into a smaller one focused on a single task. Not summarisation in general, summarisation for your domain. Not classification broadly, classification against your categories. Each model does one thing well. We then connect several of these small models so they can handle more complex, multi-step work as a team.

Efficiency Through Fine-Tuning: No Need for Reasoning during Inference
During distillation, we use reasoning heavily. The "teacher" model, a large general-purpose LLM, reasons through each training example carefully before producing an answer. That reasoning is what makes the training data good.
But once a small model has learned from those examples, it doesn't need to reason anymore. It's internalised the patterns. When deployed, it just answers. No chain of thought, no working through the problem step by step. It goes straight to the output.
That's not a shortcut. It's the point. Our models respond in milliseconds. DeepSeek-R1 can take up to 10 minutes. GPU costs come in under $1,000 per month for our models, versus roughly $30,000 per month for running DeepSeek-R1 at scale. For a business that needs AI embedded in a real workflow, those numbers matter a lot.
Model Agnostic: Tailored Architectures for Each Task
We don't have a single house model. Different tasks call for different architectures, and we pick accordingly.
For classification, BERT-style models are still the gold standard: they're small (around 300 million parameters), fast, and highly accurate for the task. That's a fraction of DeepSeek-R1's 671 billion parameters. There's no good reason to run a massive general model for a job a focused small one handles better.
Our edge isn't in picking the newest or largest model. It's in distillation, using synthetic data generation to teach the right model the right things. The goal is always the same: maximum accuracy on your specific task, with as little overhead as possible in production.