Thought leadership
Revolut's PRAGMA proves the case for small, domain-specific models in financial services
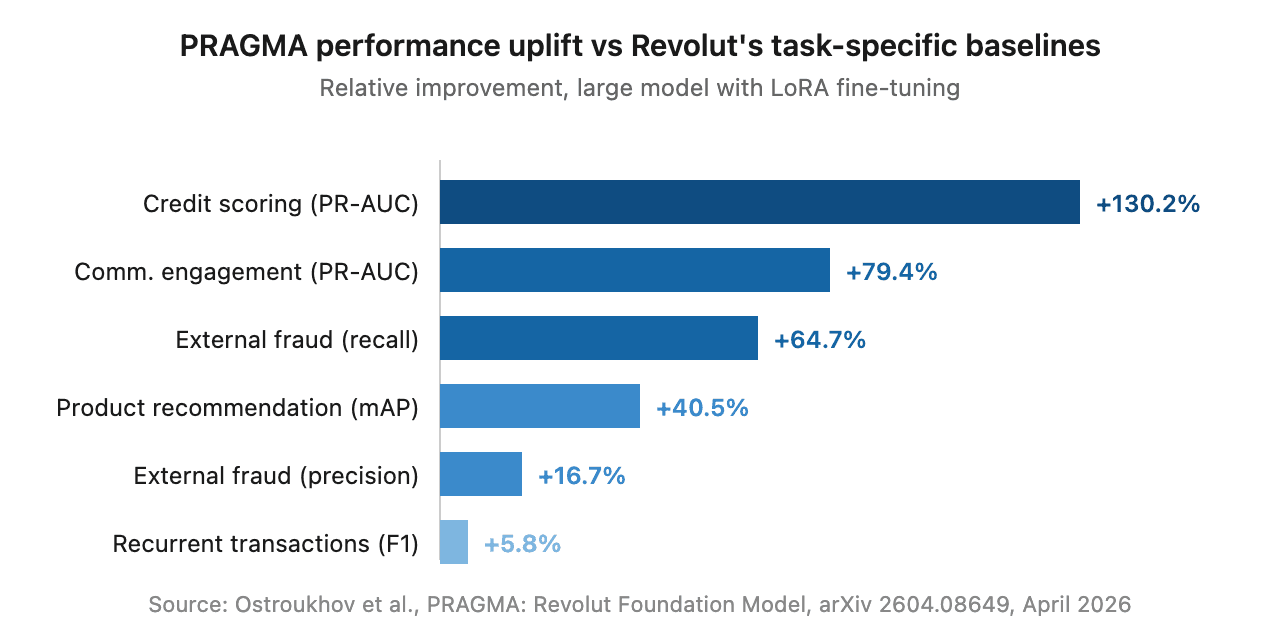
In April, Revolut and NVIDIA published PRAGMA on arXiv — a family of encoder-style foundation models trained on 24 billion banking events from 26 million users across 111 countries. The headline numbers are arresting: credit scoring up 130%, fraud recall up 65%, communication engagement up 79% against Revolut's own internal baselines.

But the technical paper isn't really the story. In the past twelve months, Stripe, Mastercard, Visa, Nubank and now Revolut have all built their own foundation models for financial data. PayPal fine-tuned Llama. NPCI fine-tuned Mistral for India's UPI network. The pattern is consistent and accelerating, and it tells us something specific about where enterprise AI in financial services is going.
Domain-specific, smaller models trained on proprietary data are quietly replacing general-purpose frontier APIs for the tasks that matter most in regulated finance. Building one yourself, like Revolut did, isn't the only path – and for most institutions, it shouldn't be.
What PRAGMA actually is
Worth being precise: PRAGMA isn't a small language model in the strict sense, but rather a small event model, designed to capture and model temporal dynamics. It scales from 10 million to 1 billion parameters across three encoder branches — one for static profile data, one for individual events, one fusing them into user-level history. After pre-training, Revolut adapted the backbone to specific tasks using LoRA fine-tuning, updating only 2–4% of weights per task.
A single shared backbone outperformed task-specific baselines that Revolut's data science teams had spent years tuning, across credit scoring, fraud, lifetime value, communication engagement, recurrent transactions and product recommendation.
Why this validates the small-model thesis
The technical detail matters less than the strategic move. Revolut, sitting on years of granular behavioural data, decided that calling a frontier LLM via API wasn't good enough for the use cases that actually move the business. They built something narrower, smaller and trained on data nobody else has. And it dramatically beat their internal baselines.
This isn't an isolated observation. Gartner forecasts that more than half of enterprise GenAI models will be domain-specific by 2027, up from 1% in 2024. The reasons are familiar to anyone deploying AI in regulated finance: cost (private SLM endpoints typically run 5× to 20× cheaper than equivalent frontier API traffic), latency (sub-100ms inference is the floor for real-time decisions), privacy (single-tenant deployment sidesteps an entire category of compliance risk), and explainability (a 400M-parameter specialist is far easier to defend in a regulator's office than a 1.8 trillion-parameter generalist).
But not every firm is Revolut
Building something like PRAGMA is genuinely hard. It needs petabyte-scale data nobody else has access to, many H100 GPUs, weeks of training time, and a research team with deep ML and banking expertise in one room. The technique itself isn’t secret. The real complexity lies in the data, the people, and the systems required to keep it continuously updated.
Most financial institutions don't have any of that. For the vast majority, the realistic path is partnering with specialists who already have the technical foundations and domain context — or buying purpose-built solutions for specific high-value use cases. The data moat doesn't have to be petabyte-scale either. For many tasks, a few thousand carefully curated records from your own operations is enough, provided the architecture and evaluation are right.
We've seen this directly. In 2025, we worked with the FCA on a proof of concept for multilabel classification — the kind of high-volume task that runs underneath customer routing, KYC/KYB, complaint triage and vulnerability detection across the industry. Using a 400 million parameter model trained on around 10,000 records, deployed in a single tenant environment with no data sub-processors, the SLM achieved "zero missed high risk classifications, alongside materially higher accuracy than a prompted general LLM on the same task. We also observed significantly faster latency, with large reductions in compute cost and energy usage for the use cases in scope."
As Edmund Towers, Head of Advanced Analytics and Data Science at the FCA, framed it: "This proof of concept reflects the FCA's commitment to innovation that is grounded in responsible choices. As AI continues to evolve rapidly, it is essential to understand how technical design decisions connect directly to risk appetite, transparency, and trust."
What this means
Revolut's PRAGMA paper, taken alongside the broader pattern, settles an argument the industry has been having for two years. Domain-specific, smaller models trained on proprietary data outperform general-purpose frontier models for the tasks that actually matter in regulated financial services. Cost, latency, privacy, explainability and accuracy all point the same way.
The strategic question for most institutions isn't should we build our own foundation model — almost always the answer to that is no. It's which of our high-value tasks would benefit from a domain-specific model, and what's the fastest way to get one into production? For some, that means building. For most, it means partnering. For others, buying. The PRAGMA paper is, among other things, permission to have that conversation.
Malted builds small, domain-specific language models for financial services, focused on customer contact data. If you'd like to talk about where they might fit into your AI strategy, get in touch.