Research
Small vs. Large Language Models: Pipelines, Performance, and Purpose

Alessandro Speggiorin
Most conversations about AI focus on the biggest names: GPT-4, Claude, Gemini. But size isn't always the point. Depending on what you actually need AI to do, a much smaller model might do the job better, faster, and for a fraction of the cost.
This article breaks down the key differences between Large Language Models (LLMs) and Small Language Models (SLMs): how they're built, where each one performs, and what happens when you stop trying to find one model that does everything and instead build a team of small ones.

Key Takeaways
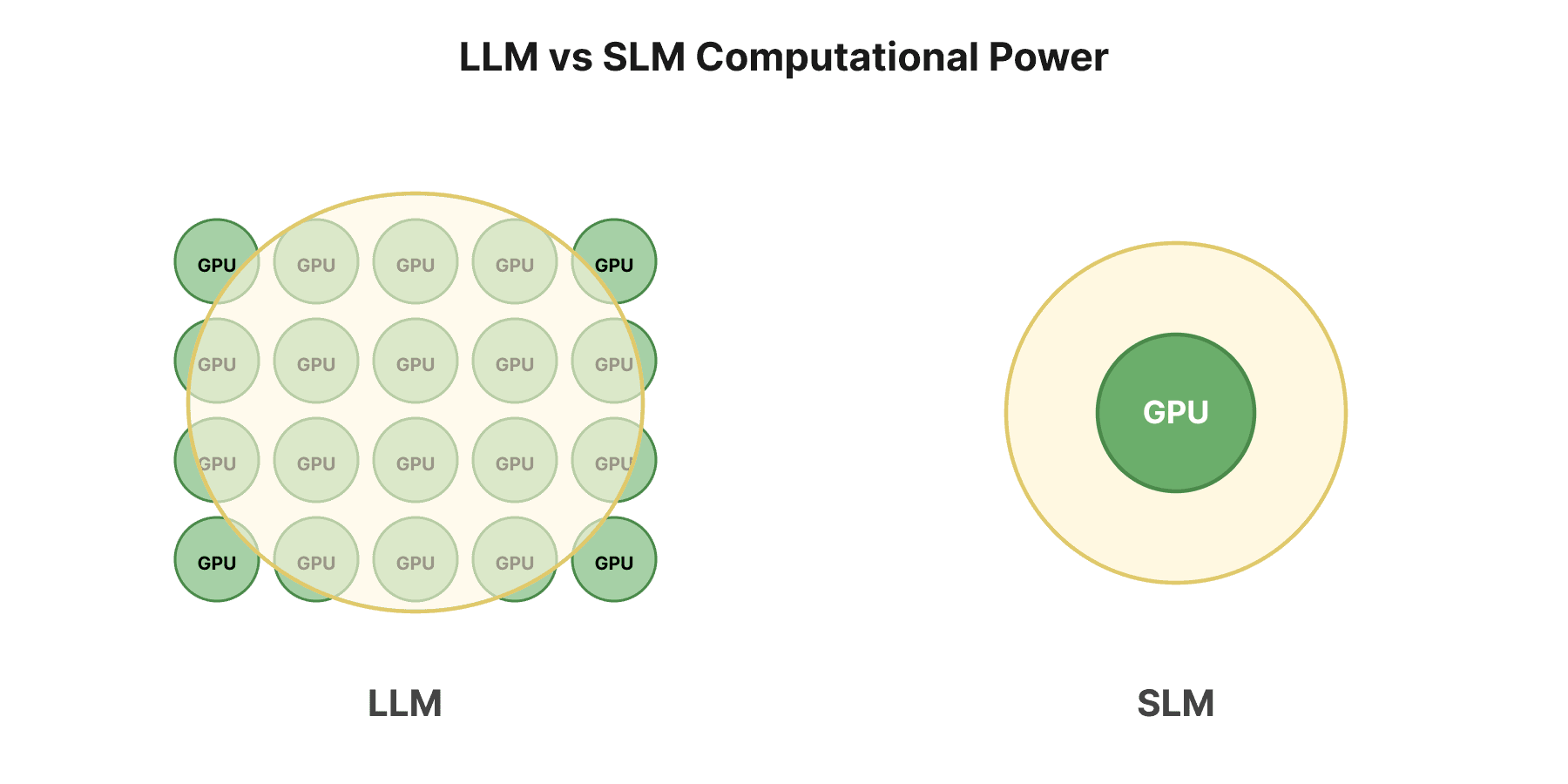
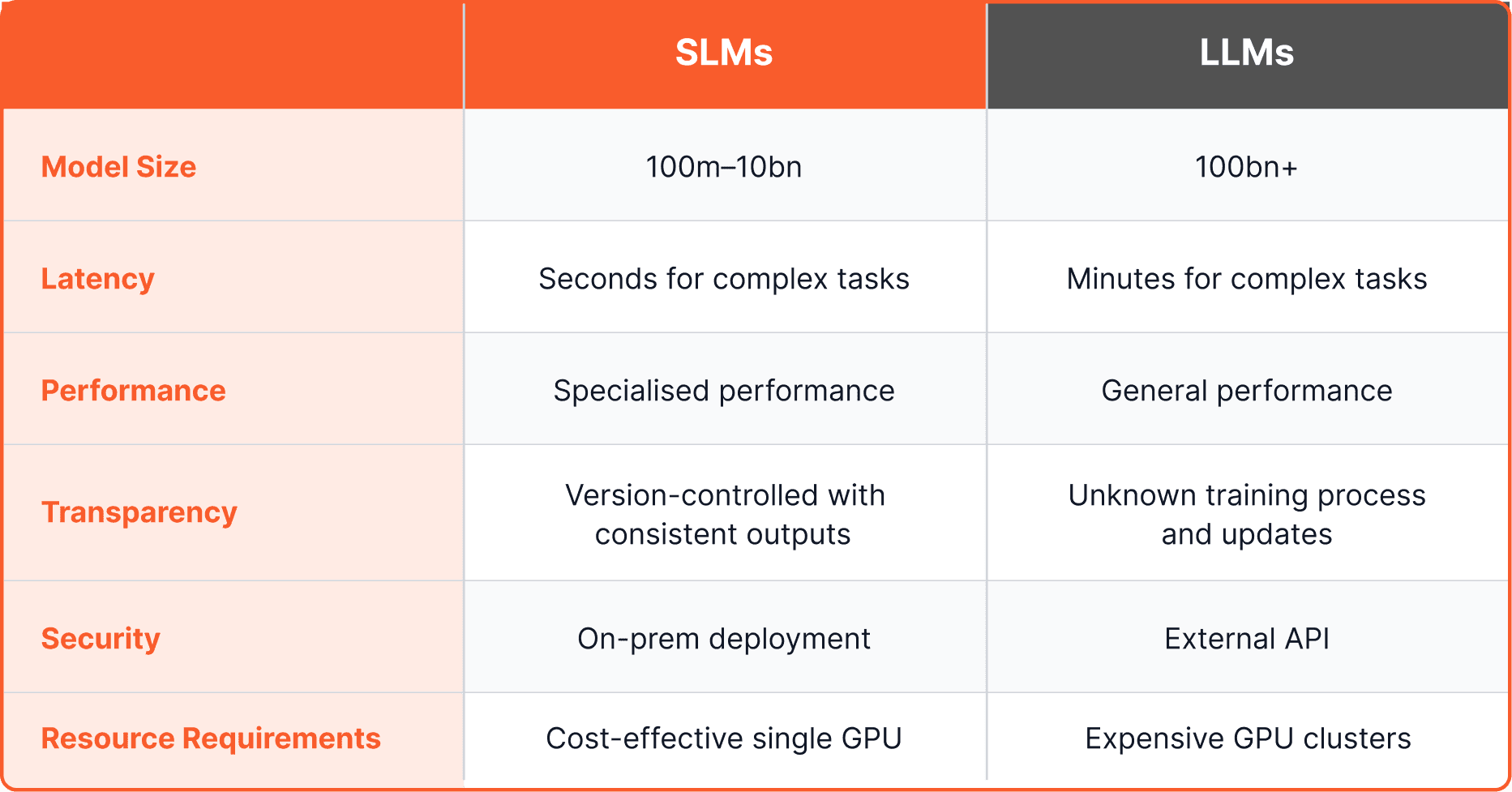
LLMs have 100 billion+ parameters; SLMs typically sit between 100 million and 10 billion
SLMs run on a single GPU for a few thousand pounds a month; LLMs can run into millions annually
LLMs are generalists; SLMs are specialists trained for specific tasks
Chaining multiple SLMs in a pipeline consistently outperforms a single LLM on complex, structured enterprise tasks
What Is a Language Model?
Both LLMs and SLMs work the same basic way. They're trained on large amounts of text, and they learn to predict which word comes next based on patterns absorbed during training. Give one a question and it builds a response token by token, drawing on everything it saw while being trained.
The difference between an LLM and an SLM isn't the mechanism. It's scale, cost, and what each one is built to do.
LLMs vs SLMs: Core Differences
Model Size and Complexity
The most visible difference is parameter count, which roughly corresponds to the model's capacity to learn patterns. Think of parameters as the model's memory. More means greater capacity to pick up on subtle, complex relationships in data (1).

LLMs typically have over 100 billion parameters. The largest push past 1 trillion. GPT-4 is estimated at 1.4 trillion. SLMs sit between 100 million and 10 billion; Malted AI's models run at 800 million. That gap has direct consequences for cost, speed, and what each type of model is actually good at.
Efficiency, Speed and Cost
More parameters means more compute. LLMs need clusters of high-performance GPUs to run, and the infrastructure costs reflect that: we're talking millions of pounds a year for serious deployments (2). They're also slower. All that computation takes time, and in high-volume or real-time applications, the latency compounds quickly.
SLMs run on a single GPU. Infrastructure costs typically land in the thousands per month, not millions (3). Response times are far quicker, which makes them practical for production systems where speed is part of the product.
There's an environmental angle here too. The energy required to train and maintain LLMs is significant. SLMs have a much lighter footprint (2).
Training Data Requirements
Training an LLM requires enormous, diverse datasets, often pulled from broad web crawls, to give the model enough exposure to work across many topics and tasks (4). That's part of what makes them expensive to build.
SLMs need far less data, and they train faster (5). That also makes them well suited to domain-specific datasets, where precision in a narrow area matters more than breadth across everything.
Generalists vs Specialists
LLMs are built to know a bit about everything. Ask one to summarise a legal document, write marketing copy, or explain a technical concept, and it'll usually give you something plausible. That breadth is genuinely useful in some contexts.
But plausible isn't the same as accurate, and for many enterprise tasks, that gap matters. If your job is classifying documents according to your company's internal taxonomy, or pulling specific data fields from contracts, the LLM's general training works against it. It hasn't seen your terminology, your categories, or your edge cases.
SLMs go the other way: narrow, specific, and highly accurate within their area (6, 7). They don't try to know everything. They know one thing well.
Privacy and Security
LLMs typically run via external APIs, which means your data leaves your infrastructure to be processed on someone else's servers (8). In healthcare, financial services, or banking, that's often a non-starter.
SLMs can be deployed on-premise. Data stays in your environment. That's a meaningful security advantage for any application where data privacy is a hard requirement, not just a preference.
For most enterprise use cases, LLMs struggle to justify their cost. The ROI gets difficult when you're paying for capability you don't use, and getting accuracy that's often worse than a smaller, focused model on the specific task you care about.
SLMs vs LLMs: When to Choose Which?
Choose SLMs when:
Compute resources are limited and infrastructure cost matters
The task is well-defined and sits within a specific domain
You need fast, consistent responses at scale
Data privacy or on-premise deployment is a requirement
Choose LLMs when:
You have the infrastructure and budget to support them
The task is genuinely open-ended, requiring broad generalisation
You need creative generation, flexible conversation, or long-form responses across varied topics
Specificity isn't the priority and coverage is
Worth flagging: for most enterprise use cases, LLMs struggle to justify their cost. The ROI gets difficult when you're paying for capability you don't use, and getting accuracy that's often worse than a smaller, focused model on the specific task you care about.
Our Approach: Pipelines of SLMs
A single LLM and a single SLM both have the same fundamental problem when applied to complex, multi-step tasks. The LLM is too broad to be precise. The SLM is too narrow to handle the whole thing.
The solution is pipelines.
Think of it like building a car. You could hire one person with broad general knowledge about cars. They'd build something functional. But they'd make compromises throughout, choosing materials that mostly work, fitting parts to rough tolerances, painting with whatever's available. The result runs. It's just not that good.
Now imagine you assembled a team of specialists: someone who does nothing but wheels, another who selects paint based on the specific material and environment, another focused entirely on the engine. Each one executes their part precisely. Together they build something much better.
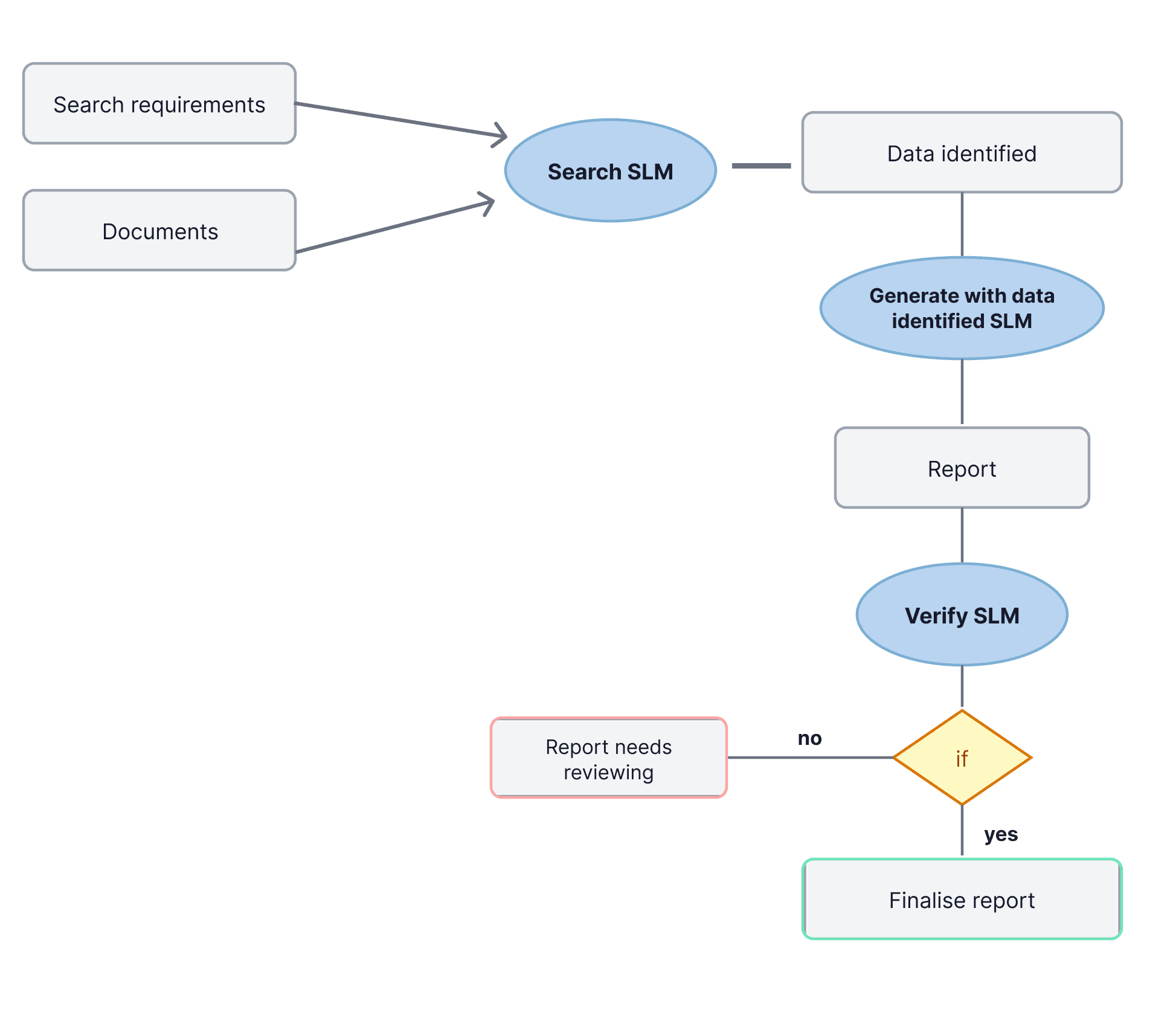
That's how we approach AI at Malted AI. We chain together multiple SLMs, each trained for one specific part of a task. The output of one becomes the input of the next.
Take document processing: searching a collection of files, extracting relevant information, and producing a report. In a pipeline, a search SLM finds the relevant data. A second SLM generates the report from that data. A third verifies the output against the original criteria, flags inconsistencies, and either signs off or routes it back for review. Each model does one thing. Each does it well.
This approach also makes the system easier to maintain. If one step needs updating, you retrain that model. The rest stays untouched.
Conclusion
LLMs and SLMs aren't competing technologies. They're tools with different strengths, suited to different jobs. For open-ended, creative, or broad tasks, LLMs have real value. For precise, domain-specific work that needs to run reliably in production, SLMs are usually the better choice, especially when combined into pipelines.
We've seen SLMs chained together handle tasks where single large models fall short: consistently, quickly, and at a cost that actually makes sense for enterprise deployment. The field is still developing, and there's plenty more to unlock. But for tasks that demand accuracy and domain knowledge, the pipeline approach is where we'd focus.
References
Brown, T. B. et al. "Language models are few-shot learners." arXiv:2005.14165 (2020).
Schick, T. and Schütze, H. "It's not just size that matters: Small language models are also few-shot learners." arXiv:2009.07118 (2020).
Thawakar, O. et al. "Mobillama: Towards accurate and lightweight fully transparent GPT." arXiv:2402.16840 (2024).
Zhao, W. X. et al. "A survey of large language models." arXiv:2303.18223 (2023).
Vemulapalli, R. et al. "Label-efficient Training of Small Task-specific Models by Leveraging Vision Foundation Models." (2023).
Fu, Y. et al. "Specializing smaller language models towards multi-step reasoning." ICML. PMLR, 2023.
Zhan, X. et al. "SLM-Mod: Small Language Models Surpass LLMs at Content Moderation." arXiv:2410.13155 (2024).
Wang, X. et al. "Efficient and Personalized Mobile Health Event Prediction via Small Language Models." arXiv:2409.18987 (2024).