This blog post explores how knowledge distillation, combined with synthetic data, enables the development of small, efficient AI models that retain the capabilities of larger ones, addressing data scarcity, reducing resource requirements, and delivering practical and secure solutions for enterprise applications.
Access to quality data remains a persistent challenge for organisations striving to build effective, high-performing AI systems. Data is not always readily available, and when it is, it often lacks the necessary annotations for training AI applications. This is where knowledge distillation, coupled with synthetic data, offers a transformative solution.
In this blog, we will explore the concept of knowledge distillation, its benefits, and how it can be applied to enterprises. We’ll focus on how synthetic data and small language models can be leveraged to overcome limitations with existing data.
Language models have been studied for decades, but the adoption of modern AI models, particularly those based on transformers, has surged only recently. From their inception, researchers have focused on scaling these models to enhance their power and performance. This progress has underscored the differences between large and small language models, along with the distinct challenges Gen AI poses in enterprise contexts, particularly regarding cost, security, and scalability. For a more detailed exploration of small versus large language models, refer to our previous blog.
Knowledge distillation is the key methodology that enables smaller models to retain the power of larger models, opening up a new approach to obtaining and accelerating value from AI.
Knowledge distillation, introduced by Hinton et al. (2015) (1), is a method for transferring knowledge from a large, complex model (the “teacher”) to a smaller, more efficient model (the “student”). The aim is to create a highly task-specific student model that remains computationally efficient and suitable for resource-constrained environments. By distilling the teacher’s insights, the student model achieves high performance while being smaller, faster, and more practical for deployment.
A crucial element of knowledge distillation is the use of soft labels. Unlike hard labels, which provide fixed answers (e.g., relevant/not relevant), soft labels assign probabilities to all possible outcomes, not just the most likely ones. For example, instead of saying “this image is a cat,” the teacher model might output a probability distribution, such as 0.7 for “cat”, 0.2 for “dog”, and 0.1 for “bird” (1). These soft labels provide richer information about the teacher’s understanding, including its confidence and uncertainty about the classification. This allows the student model to learn not just the correct class but also the relationships and nuances between classes, improving its ability to generalise with fewer data points (2).
Soft labels also play a key role in synthetic data generation. In data-scarce environments, the teacher model can generate high-quality synthetic data in the form of soft labels for inputs that may not have explicit ground-truth labels. Ground-truth labels refer to data that has been accurately annotated to indicate the correct outcome or classification, such as whether an image contains a cat or a dog. However, in many cases, obtaining these labels can be costly or impractical. For example, labelling large datasets often requires expert input, which can cost thousands of pounds or months of effort for datasets involving subjective or complex tasks. Furthermore, changes in the problem domain, such as introducing new categories or modifying definitions, may require re-labelling entire datasets, adding further expense and delay.
Therefore, soft labels offer an effective and practical solution in these situations. By assigning soft labels to new, unlabelled, or even noisy data points, the teacher model can provide valuable guidance to the student model, enhancing its learning process and improving overall performance (3). These synthetic examples act as a form of data augmentation, allowing the student to expand its knowledge base without needing a large volume of labelled data (4).
For example in financial services, synthetic data can be used to simulate customer credit behaviors to improve credit risk modeling. A teacher model can generate synthetic profiles of borrowers, including rare but critical scenarios such as sudden income changes, unexpected high debt accumulation, or irregular repayment patterns. These synthetic profiles can also represent underrepresented groups or edge cases lacking large amounts of data, such as individuals with limited credit histories or unconventional financial behaviours.
The process of knowledge distillation involves several steps that enable a smaller, more efficient student model to benefit from the knowledge encoded in a larger, more complex teacher model.
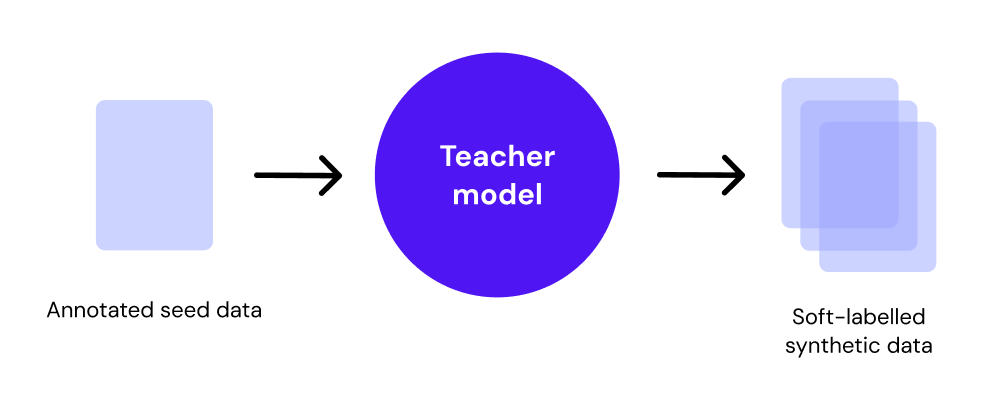
The first step is to train the teacher model on domain-specific data. In many instances, seed data, a carefully selected subset of task-specific and representative data, is used to effectively represent the broader dataset and use cases. Seed data ensures that the teacher model learns the most important patterns and relationships within the data. The teacher then encodes high-level abstractions that the student will later learn (5).
Once the teacher is trained, soft labels for the data are generated, which are probability distributions over possible classes. These soft labels contain richer information than hard labels, capturing the teacher’s confidence in its predictions and its understanding of relationships between classes. The teacher’s output is not limited to the most likely class but instead reflects a more nuanced view of the data (6).
The teacher can also be used to generate synthetic data, which, like the soft labels, embodies the teacher’s learned representations and understanding of the data. This synthetic data provides additional examples where the teacher’s confidence is encoded, effectively serving as soft labels. The student model can then learn from these synthetic instances, gaining a richer understanding of the task.
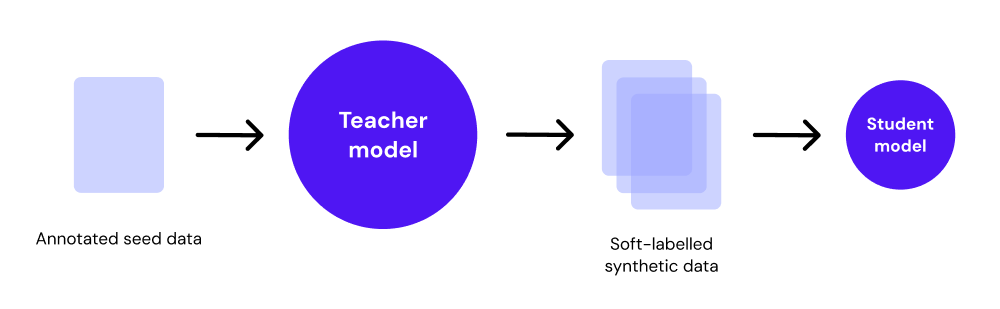
The student model, a small language model, is then trained to replicate the teacher’s output distributions. This process allows the student model to absorb not only the correct predictions but also the underlying patterns the teacher has learned, enabling it to generalise effectively despite being computationally smaller (7). To ensure alignment between the student and teacher, Kullback-Leibler (KL) divergence is often employed. KL divergence minimises the difference between the student’s predicted probability distribution and the teacher’s soft labels, ensuring that the student captures both the correct predictions and the teacher’s confidence levels (2).
By leveraging seed data for the teacher’s training and utilising soft labels, knowledge distillation empowers the student model to learn from both real-world data and the insights encoded by the teacher. This process makes the student model more efficient and focused, even in resource-constrained settings.
To illustrate the impact of knowledge distillation, consider the example of distilling a large 70-billion-parameter LLaMA model for a re-ranking task in search, which involves rearranging search results based on relevance. Interference with such a large model requires substantial computational resources, taking weeks or months with high-performance GPUs. By distilling the knowledge into a smaller student model, like T5, the task can still be performed accurately while using far fewer resources. The smaller T5 model can handle search re-ranking efficiently, requiring just one GPU instead of a large cluster, reducing both operational costs and energy consumption.
At Malted AI, knowledge distillation is a cornerstone of our approach, enabling us to train small, task-specific language models capable of addressing the most challenging AI problems in regulated domains such as finance. By distilling knowledge from a teacher model trained on high-quality seed data, we produce lightweight, efficient student models tailored to excel in their specific tasks. These models not only overcome data scarcity but also operate effectively in resource-constrained environments, making them practical for real-world applications.
What sets our approach apart is the ability to chain these specialised models into pipelines, unlocking sophisticated, multi-step behaviours. Each small language model is an expert in its domain and task, and together, they form powerful systems capable of tackling complex challenges. This modular, efficient approach allows us to deliver state-of-the-art AI solutions across critical and data-sensitive fields.
A core feature of our methodology is the continuous improvement of these models as they are used in real-world applications. As the models interact with new data and examples, they adapt, refining their understanding and performance. This ongoing learning process ensures that the models become increasingly proficient at their tasks over time. Furthermore, as new examples are provided, the models can be distilled again, enhancing their factual accuracy and ensuring that they remain at the forefront of their field.